Quora Insincere Questions

Kaggle Competition hosted by Quora for improving its online conversations [link].
Quora is a platform that empowers people to learn from each other. On Quora, people can ask questions and connect with others who contribute unique insights and quality answers. A key challenge is to weed out insincere questions — those founded upon false premises, or that intend to make a statement rather than looking for helpful answers.
As this was a kernel only competition, external data sources were not allowed. We have to submit the kaggle kernel(either notebook or script) with all the code and output predictions in the specific format as mentioned in the submission requirements.
In this competition it will be develop models that identify and flag insincere questions.
General Description
An insincere question is defned as a question intended to make a statement rather than look for helpful answers. Some characteristics tha can signify that a question is insincere:
Has a non-neutral tone
- Has an exaggerated tone to underscore a point about a group of people.
- Is rhetorical and meant to impy a statement about a group of people.
Is disparaging or inflammatory
- Suggests a discriminatory idea against a protected class of people, or seeks confirmation of a stereotype.
- Makes desparaging attacks/insults against a specific person or group of people.
- Disparages against a characteristic that is not fixable and not measurable.
Isn't grounded in reality
- Based on false information, or contains absurd assumptions.
File Description
- train.csv - the training set.
- test.csv - the test set.
- sample_submission.csv - A sample submission in the correct format.
Performance Metric
Source:https://www.kaggle.com/c/quora-insincere-questions-classification/overview/evaluation
- [F1 Score] (https://en.wikipedia.org/wiki/F1_score)
Along with the question's text data, quora had also provided 4 different embedding files trained on large corpus of data that can be used in the models. Given embedding files are as follows:
- Google News — vectors
- Glove
- Paragram
- Wiki-news
Exploratory Data Analysis
Data fields- qid- unique question identifier.
- question_text - Quora question text.
- target - A question labeled "insincere" has a value of 1, otherwise 0.
Distribution of data points among output class

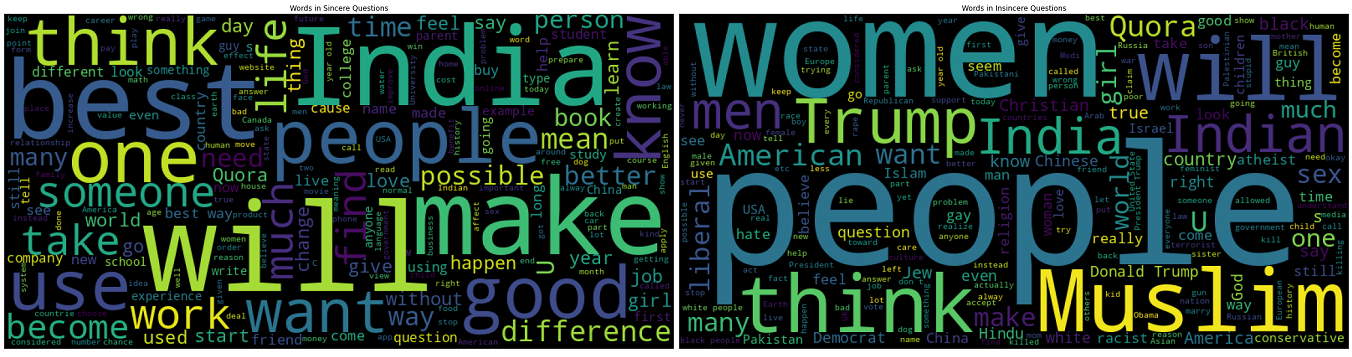
Word cloud for both sincere and insincere questions
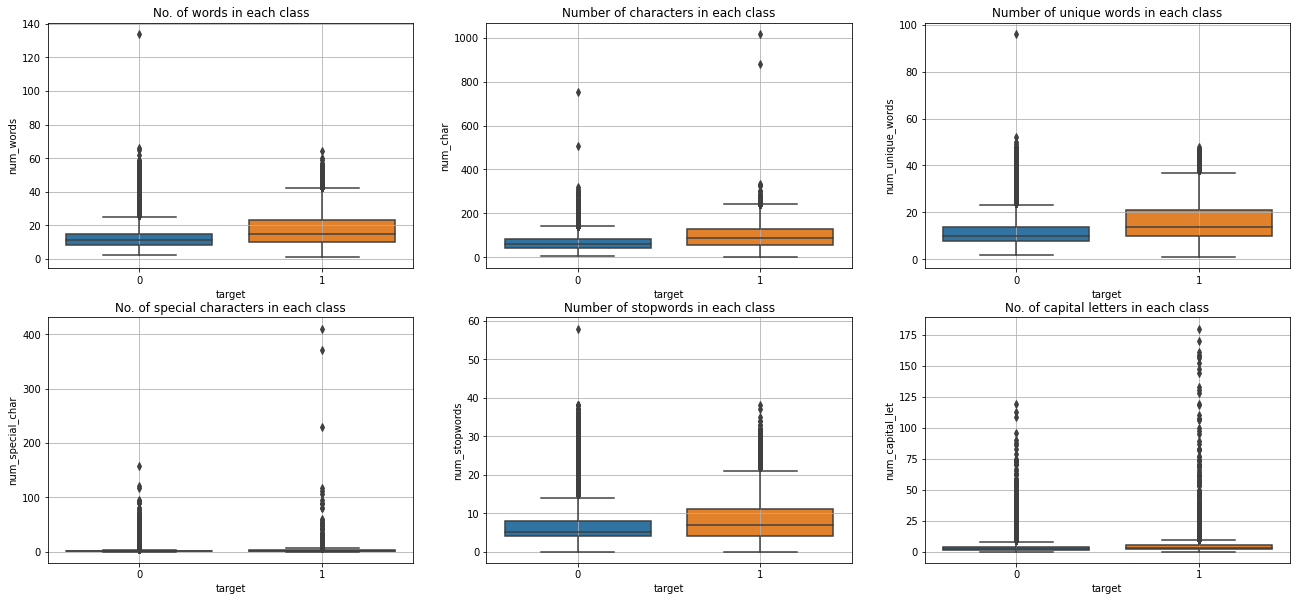
Analysis on extracted features
Basic Feauture Extraction(before cleaning):
- num_words= Number of words in question.
- num_capital_let= Number of capital letters in the question.
- num_special_char = Number of special characters in the question.
- num_unique_words = Number of unique words in the question.
- num_numerics = Number of numerics in the question.
- num_char = Number of characters in Question.
- num_stopwords = Number of stopwords in the question.
Observations from the EDA:
- Data is highly imbalanced with only 6.2% of insincere questions.
- F1-Score seems to be right choice than accuracy here because of data imbalance.
- As we can see insincere questions contain many of the offensive words.
- Most of the questions are related to *People*, *Muslim*, *Women*, *India*, *Trump*, etc.
- Insincere questions seems to have more words and characters.
- Insincere questions also have more unique words compare to sincere questions.
- Looks like there are some math questions(most of them are classified as insincere) in the data which contains more special chars and numbers.
- Some questions also contains emojis and non-english characters.
Data Preprocessing and Cleaning
The data is quite messy, there are lots of words that are mispelled, and some special symbols, which can not got corresponding embeddings, so before put into model, we need to clean those mispelled words and clean out the special symbols. Also, those mispelled words and special symbols could have some information, e.g., questions have mispelled words or special symbols would be more possible to be an insincere question, so I also marked them during cleaning up process.
The following steps have been followed:
- Replacing math equations with common abbrevation.
- Removing punctuations.
- Removing Numbers.
- Cleaning contractions.
- Feature extraction II.
- Spell Correction.
- Data Cleaning.
As a good practice in this case, Spacy was used for the creation of our words sequences, word and lemma dictionaries. These 2 dictionaries were later used to create the embedding matrix. During our experimentation, a method was used in which many operations were performed, but in our most recent version at the end of the method itself they were ignored by example other features that could be useful in other resolutions.
Embedding
For increasing embeddings coverage I have used the combination of word stemming, lemmatization, capitalization, lowercase, uppercase as well as embedding of the nearest word using spell checker(using the wiki-news embedding) to get embeddings for all words in vocab. Created two separate embedding matrices with Glove and Paragran embedding files. Finally, taken weighted average of them giving higher weightage to glove.
embedding_matrix_glove, nb_words = load_embeddings(word_dict, lemma_dict, 'glove')
embedding_matrix_para, nb_words = load_embeddings(word_dict, lemma_dict, 'para')
embedding_matrix = np.mean((1.28*embedding_matrix_glove, 0.72*embedding_matrix_para), axis=0)
Models
After creating the embedding matrix, I built an ensemble of two different models' architectures to capture different aspects of the dataset and thus increasing overall F1-Score. In order to do that, I used Blending technique, which uses a machine learning model to learn how to best combine the predictions from multiple contributing ensemble member models.
At first, I developped three models, one of the TextCNN type and the other two of the Bidirectional RNN(LSTM) type. Finally, I got the best results with an emsemble of the last two as I mentioned before.
Let's take a closer look at these last two models.
Bidirectional RNN(LSTM)
Recurrent Neural Network(RNN) are a type of Neural Network where the output from previous steps are fed as input to the current step, thus remembers some information about the sequence. It has limitations like difficulty in remembering longer sequences. LSTM/GRU are improved versions of RNN, specialized in remembering information for an extended period using a gating mechanism which RNN fails to do.
Unidirectional RNN's only preserves information of the past because the inputs it has seen are from the past. Using bidirectional will run the inputs in two ways, one from past to future and one from future to past allowing it to preserve contextual information from both past and future at any point of time.
Arquitecture
max_features_temp = len(word_dict)+1
inp = Input(shape=(params['maxlen'],))
x = Embedding(max_features_temp, params['embed_size'], weights=[embedding_matrix])(inp)
x = Bidirectional(LSTM(64, return_sequences=True))(x)
x = GlobalMaxPool1D()(x)
x = Dense(16, activation="relu")(x)
x = Dropout(0.1)(x)
x = Dense(1, activation="sigmoid")(x)
model1 = Model(inputs=inp, outputs=x)
model1.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
Bidirectional RNN(LSTM) II
This model consists of Bidirectional LSTM followed by Convolutional and pooling layers. The idea behind using CNNs in NLP is to make use of their ability to extract features. CNNs are applied to embedding vectors of a given sentence with the hopes that they'll manage to extract useful features(such as phrases and relationships between words that are closer together in the sentence) which can be used for text classification.
The NLP CNN is usually made up of 3 or more 1D convolutional and pooling layers unlike traditional CNNs. This helps reduce the dimensionality of the text and acts as a summary of sorts which is then fed to a series of dense layers.
Arquitecture
max_features_temp = len(word_dict)+1
spatialdropout=0.2
rnn_units=128
filters=[100, 80, 30, 12]
inp = Input(shape=(params['maxlen'],))
emb = Embedding(max_features_temp, params['embed_size'], weights=[embedding_matrix], name='Embedding')(inp)
x = SpatialDropout1D(rate=spatialdropout, seed=10000)(emb)
rnn = Bidirectional(CuDNNLSTM(rnn_units, return_sequences=True, kernel_initializer=initializers.glorot_uniform(seed=123000), recurrent_initializer=initializers.Orthogonal(gain=1.0, seed=123000)))(x)
x1 = Conv1D(filters=filters[0], activation='relu', kernel_size=1, padding='same', kernel_initializer=initializers.glorot_uniform(seed=110000))(rnn)
x2 = Conv1D(filters=filters[1], activation='relu', kernel_size=1, padding='same', kernel_initializer=initializers.glorot_uniform(seed=120000))(rnn)
x3 = Conv1D(filters=filters[2], activation='relu', kernel_size=1, padding='same', kernel_initializer=initializers.glorot_uniform(seed=130000))(rnn)
x4 = Conv1D(filters=filters[3], activation='relu', kernel_size=1, padding='same', kernel_initializer=initializers.glorot_uniform(seed=140000))(rnn)
x1 = GlobalMaxPooling1D()(x1)
x2 = GlobalMaxPooling1D()(x2)
x3 = GlobalMaxPooling1D()(x3)
x4 = GlobalMaxPooling1D()(x4)
c = concatenate([x1, x2, x3, x4])
x = Dense(200, activation='relu', kernel_initializer=initializers.glorot_uniform(seed=111000))(c)
x = Dropout(0.2, seed=10000)(x)
x = BatchNormalization()(x)
x_output = Dense(1, activation='sigmoid', kernel_initializer=initializers.glorot_uniform(seed=110000))(x)
model2 = Model(inputs=inp, outputs=x_output)
model2.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
Blending
In this case its used a simple lineal combination of the two best models looking for a better score.
final_preds_val = 0.5*pred_modelBRNN_x_val+0.5*pred_modelBRNN2_x_val
final_preds = 0.5*pred_modelBRNN+0.5*pred_modelBRNN2
Submission
The metric used in the competition is the F-1 Score, which could not be directly optimized. To approximately optimize it, I tried to find an optimal threshold to make the hard classification. But one tricky thing is, a small validation set is needed to find the “best threshold”, and this threshold could vary significantly for different training.
Results
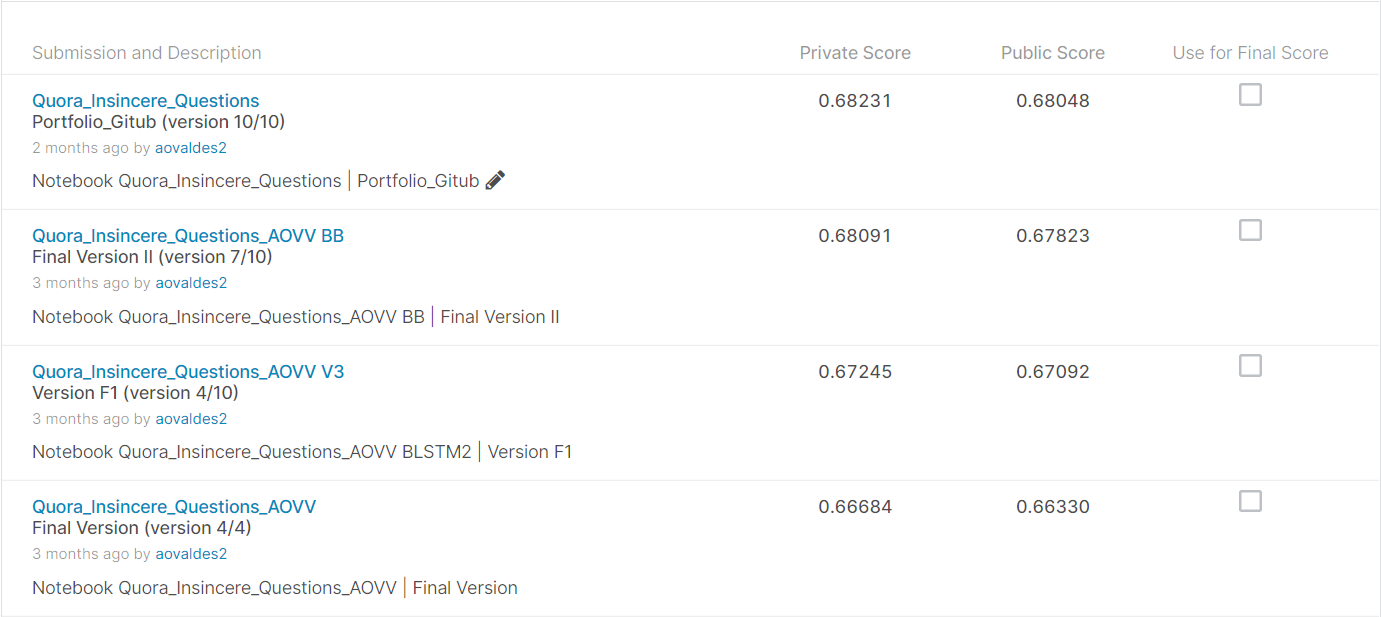
The TextCNN was descarted because it have too poorly results compared with the other models, the named Bidirectional RNN(LSTM) have an score of 0.66684 with an threshold at 0.5 meanwhile the Bidirectional RNN(LSTM)II have 0.67245 with an threshold at 0.35 then the Blending model resultant of a simple lineal combination of the two latets models had the best scores with 0.68091(threshold of 0.35) and 0.68231(threshold of 0.32).
Conclusion:
This competition had as its main peculiarity that the solutions should run with the competitor's kernels only. My solution focused on deep learning methods, and explore widely used methodologies in this field such as bidirectional RNN, Convolutions layers, Pooling layers etc. It has been an opportunity to learn a lot from kaggle forums and public solutions. Finding more word embeddings and model assembly were the key factors for improving the F1-score. The F1-score obtained from the blending method performed better than any other model that i tried, giving a private score of 0.68231. Although it could be considered a good score for the problem in question its a little far from the winnings scores(0.71323). Additional improvements can be achieved by continuing to experiment with more combinations of the layers that were used in this work, as well as using different combinations of word embeddings.